Implementing ODIN, a kNN outlier method
Version information: Updated for ELKI 0.8.0
In this tutorial, we will implement a rather simple algorithm for outlier detection, based on the in-degree of the k nearest neighbor graph. The method is called ODIN (Article on IEEExplore), and we will implement a curried version of it.
When an index such as the R*-tree, k-d-tree or LSH is added to the database, the method will run substantially faster, while this does not require any changes to the code below. We get this for free by using the kNN query functionality of ELKI.
This tutorial was developed for the KDD I class summer term 2013 and the ELKI 0.6.0 release.
Algorithm stub
We create a new class named ODIN. We implement the OutlierAlgorithm interface, but note that this does not auto-generate much code for us (see below why).
package tutorial.outlier;
import elki.data.type.TypeInformation;
import elki.outlier.OutlierAlgorithm;
public class ODIN<O> implements OutlierAlgorithm {
@Override
public TypeInformation[] getInputTypeRestriction() {
// TODO Auto-generated method stub
return null;
}
}The generics were set “agnostic” - so O can be anything; whatever data type our distance function supports!
First of all, we will be modifing the constructor: we know we are going to need a distance function distance and a parameter k, and we will make the constructor public.
Distance<? super O> distance;
int k;
public ODIN(Distance<? super O> distance, int k) {
this.distance = distance;
this.k = k;
}The input type is determined by the distance function - we can just pass on the type information (we can deal with whatever data our distance function accepts!):
@Override
public TypeInformation[] getInputTypeRestriction() {
return TypeUtil.array(distance.getInputTypeRestriction());
}The run method
We do not have a run method in the interface signature, because some algorithms need multiple relations, others only one.
Instead, we have an autorun(Database) method that uses Java introspection to find a suitable run method based on the type information given by getInputTypeRestriction.
Because we request the input data to be suitable for the distance function, we will simply get a Relation<O>:
public OutlierResult run(Relation<O> relation) {
// TODO Auto-generated method stub
return null;
}Our algorithm is based on the k nearest neighbors. Since this is an operation that can be accelerated well by a database, we will get a nearest neighbor query from the database, for our relation and distance function. The QueryBuilder will automatically use appropriate indexes (and may trigger the creation of an index by the optimizer).
KNNSearcher<DBIDRef> knnq = new QueryBuilder<>(relation, distance).kNNByDBID(k + 1);Secondly, we need to know the objects we will analyze and setup our output data store:
DBIDs ids = relation.getDBIDs();
WritableDoubleDataStore scores = DataStoreUtil.makeDoubleStorage(ids,
DataStoreFactory.HINT_DB, 0.);the best way to think of the scores is a Map<DBID, Double> - except that it will be much more efficient and use less memory. The hints are meant to allow the database to better decide which data structure to choose, and whether to keep the data in memory or save it to disk. Since these will be the output scores, we give the hint indicating that the values should go to the database: HINT_DB
Now we can process each object in the data set using an iterator:
for(DBIDIter iter = ids.iter(); iter.valid(); iter.advance()) {
// see below
}Again, the iterators in ELKI differ slightly from the Java API of Iterator<DBID> - and again, the reason is efficiency. Creating tiny objects such as DBID can cause a large overhead. The ELKI API effectively avoids this by re-using the iterator itself as reference to an object. (The iterators in ELKI are quite similar to iterators in C++, actually.)
For each object, we will acquire the k nearest neighbors (which will be accelerated if our database has e.g. an R-tree index) and then iterate of the neighbors, too:
KNNList neighbors = knnq.getKNN(iter, k);
for(DBIDIter nei = neighbors.iter(); nei.valid(); nei.advance()) {
if(DBIDUtil.equal(iter, nei)) {
continue;
}
scores.put(nei, scores.doubleValue(nei) + 1);
}For each of the neighbors, we increase the in-degree (=score) by one. We could have used integers, but doubles will be reliable enough, and postprocessing algorithms will expect double scores anyway. Note that we use DBIDUtil.equal to check whether the object is its own neighbor: in a database context, a kNN search will usually return the query object with a distance of 0! We must not use ==: the two iterators obviously are not identical. However, they may reference the same object, which is conveniently tested by DBIDUtil.equal.
The getKNN method may boil down to a slow linear scan, but the database may choose to use or add an appropriate index, the index query will be used. Then the algorithm can run in O(n k log n) or even O(n k) time.
Last but not least, we have to return our result for evaluation, visualization and post-processing. For this we need to provide some meta data on the value range and meaning of our score: minimum and maximum, but also that for this algorithm, low values indicate outlierness. We then wrap the data store in a relation and return the result (the two name strings of the relation will be used in the menus and output file names.)
double min = Double.POSITIVE_INFINITY, max = 0.0;
for(DBIDIter iter = ids.iter(); iter.valid(); iter.advance()) {
min = Math.min(min, scores.doubleValue(iter));
max = Math.max(max, scores.doubleValue(iter));
}
OutlierScoreMeta meta = new InvertedOutlierScoreMeta(min, max);
DoubleRelation rel = new MaterializedDoubleRelation(
"ODIN In-Degree", "odin", scores, ids);
return new OutlierResult(meta, rel);Adding the Parameterizer
Parameterizers in ELKI serve the purpose of connecting the UIs (both the command line and the graphical UIs) to the Java classes. Here, there are two parameters to set: the distance function distance and k.
public static class Par<O> implements Parameterizer {
@Override
public ODIN<O> make() {
return null;
}
}We now need to add a Parameter for k. We need a static OptionID, which consists of the parameter name and a description, and a Java variable to store the value in.
public static final OptionID K_ID = new OptionID("odin.k",
"Number of neighbors to use for kNN graph.");
protected Distance<? super O> distance;
protected int k;Now we can “get” the parameters in the configure method:
@Override
public void configure(Parameterization config) {
new ObjectParameter<Distance<? super O>>(Algorithm.Utils.DISTANCE_FUNCTION_ID,
Distance.class, EuclideanDistance.class) //
.grab(config, x -> distance = x);
new IntParameter(K_ID)//
// Since in a database context, the 1 nearest neighbor
// will usually be the query object itself, we require
// this value to be at least 2.
.addConstraint(CommonConstraints.GREATER_THAN_ONE_INT) //
.grab(config, x -> k = x);
}we keep the super method invokation, as this is where the distance function parameter is being set. For the k parameter, we use an IntParameter. Furthermore we add the constraint that k must be at least 2: in a database, the query object will be its own nearest neighbor! config.grab(param) will try to set the parameter, and when successful we can access its value. If the parameter was not set, config will keep track of the error. We do not want to throw an exception here - instead, all errors should be reported to the config object, so they can all be reported at once.
Now we have the distance function distance and k and can instantiate our class in the makeInstance method:
@Override
public ODIN<O> make() {
return new ODIN<>(distance, k);
}Testing the algorithm
We can now launch the GUI (or use the command line) to test our algorithm. We need to specify the k parameter (the distance function will default to Euclidean distance) and choose a data set. With our favorite “mouse” example and -odin.k 10, we get automatic visualization via a bubble plot:
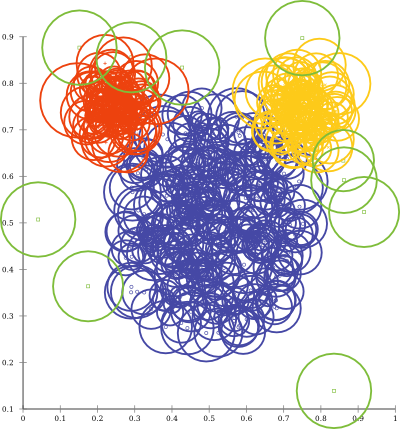
and also automatic evaluation using a ROC curve:
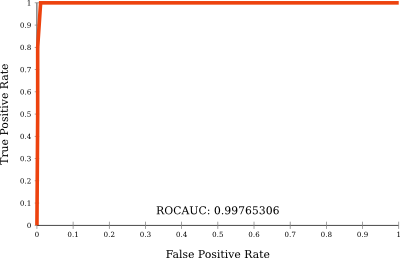
While the bubble plot is quite a mess (because the ODIN method does not return calibrated scores), we can see that the green bubbles are larger than e.g. the blue ones. The ROC plot shows us that the resulting outlier ranking is actually pretty good - almost 1.0!
Bonus: Better visualization by improving the metadata
We can actually improve above visualization quite easily, by providing additional metadata. We need to change a single line:
OutlierScoreMeta meta = new InvertedOutlierScoreMeta(min, max,
0., ids.size() - 1, k);the three additional values we added are: theoretical minimum (obviously, ODIN scores can become 0), theoretical maximum (every other object - so ids.size() - 1) and a baseline value. The baseline value is most helpful here: if we set this to the expected value for regular objects, these will be scaled to have no outlier bubble. A naive expectation is that each object will have as many in-links as it has out-links, i.e. k.
With this slight modification, the automatic visualization can produce a clearly more useful result:
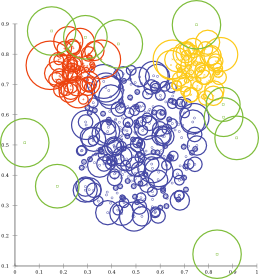
We can now tell that apparently the leftmost red objects is ranked worse than the green one just above the red cluster; this is why ODIN did not score perfect on this data set.
Bonus: add scientific reference
In order to document who came up with the idea of this algorithm, we are going to attach a scientific reference to the method. It will then show up in the documentation. For the Wiki, we put this on the page RelatedPublications.
To the class definition, we will add the following Java annotation:
@Reference(
authors="V. Hautamäki and I. Kärkkäinen and P Fränti",
title="Outlier detection using k-nearest neighbour graph",
booktitle="Proc. 17th Int. Conf. Pattern Recognition, ICPR 2004",
url="http://dx.doi.org/10.1109/ICPR.2004.1334558")
public class ODIN<O> // ...We also put the same information into the JavaDoc of the class. This makes it easier for people finding the appropriate scientific background of the algorithm that we just implemented. We should also make a note that we modified their algorithm slightly: instead of using a threshold, we “curried” the method and return the threshold at which the point would become an outlier as score.
You can browse the full source code online, in the tutorial folder